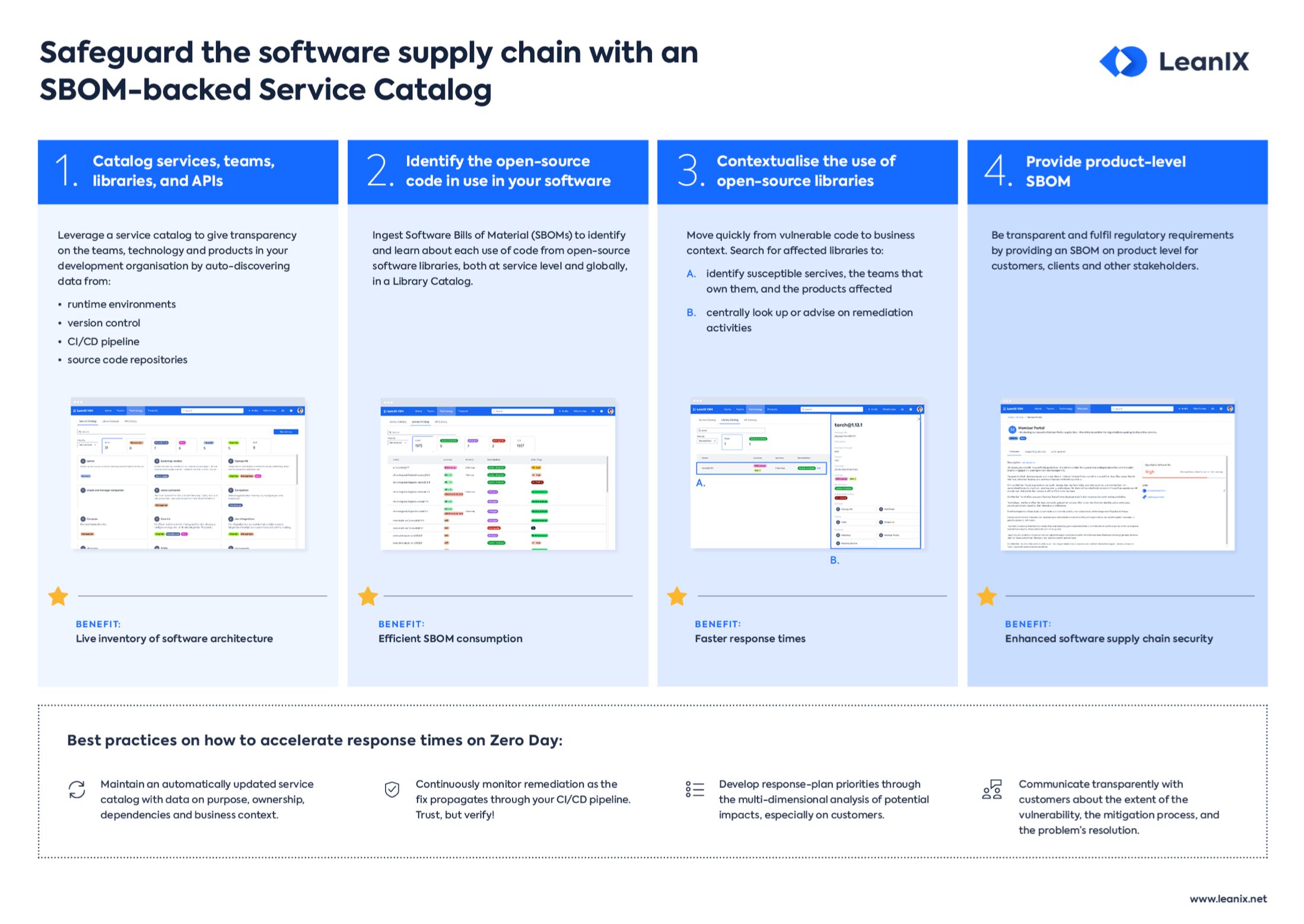
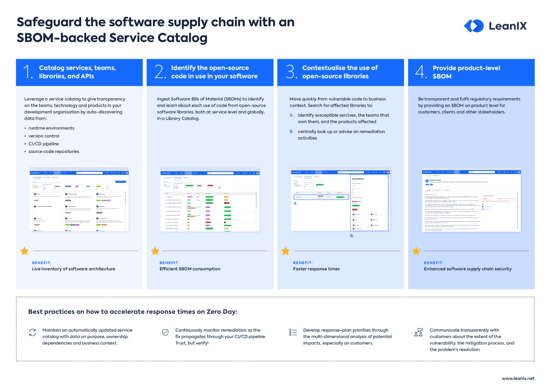
Introduction
Who needs a service catalog and how would it solve the challenges of a distributed architecture style?
In recent years, an increasing number of enterprises have replaced their monolithic systems with services. These single-function modules offer many advantages as they’re easy to integrate and easy to modify.
But while services make an organization more agile, they also add a whole new level of technical and organizational complexity that needs to be addressed.
This is where a service catalog comes in. As more and more services are added to the pile, engineering teams need to keep track of everything running in new and much more complex infrastructure. After all, it’s not unlikely that a company has up to 200 active services in place.
A service catalog aggregates all of its metadata, dependencies, and ownership information and makes it easier to take action on each service if needed.
What is a service catalog?
A service catalog or IT service catalog logs tracks all the services and systems that are part of a company’s IT architecture. It enables an organization to centrally store critical information about each service and allows developers to share this information in a live way.
The catalog not only offers a detailed view of the services themselves but also their relationships and dependencies with each other. That’s why a service catalog is not only intelligent but also continually evolving.
As new services are being developed, new dependencies make changes to the architectural structure of the IT landscape. In order to stay on top, metadata, ownership, and operational information need to be tracked and made accessible to everyone involved. Thus, like any living catalog, a service catalog needs to be properly maintained and updated.
Only if best practices are followed it can serve as a useful tool that gives companies the competitive advantage they are looking for when implementing a distributed system of services.
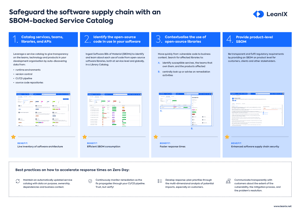
Best practices for a useful catalog
A good service catalog allows users to quickly locate and access all critical information needed in case of an incident.
It also serves as a great tool for new team members to get up to speed and develop an understanding of an enterprise’s services and how they relate to one another. If this information isn’t immediately clear or accessible, there’s a good chance the enterprise isn’t following best practices for service catalogs.
Since these best practices have already been established, development teams don’t need to reinvent the wheel and come up with their own maintenance methods.
Thus, companies can avoid investing valuable resources in setting up their own service catalog and simply rely on knowledgeable enterprise architects or use existing service catalogs as a blueprint for success.
Below are the four most important best practices for developers and architects that directly work with IT service catalogs.
1. Keep it up-to-date
A service catalog that is outdated might as well not exist at all since updated information lies at the core of its usefulness.
Thanks to automatic update reminders from the intelligent catalog itself and its ability to discover new services automatically, this doesn’t have to be an all-manual and time-consuming task.
2. Complete but continually evolving
Distributed systems are characterized by their dynamic and flexible nature which is also reflected in a good service catalog.
While it can be momentarily complete, it’s always evolving and therefore never “finalized”. However, all information that is available at a given moment should be included.
3. Easily searchable
One of the main purposes of a service catalog is to save time and resources when problems arise. That’s why searches should be easy and yield quick results.
Teams and individuals might not only be searching for a service’s name but also specific functions which should be taken into account when creating the search algorithm.
4. Avoid common mistakes
Failing to keep the service catalog updated is the most common mistake and renders it rather useless. That’s why even smaller enterprises are advised to set up a system or tool that manages updating processes.
Automatic reminders that go out to all engineers are much more effective than manual spreadsheets.
Key benefits of the catalog
An organizational system like a good service catalog helps enterprises to fully benefit from their services and supports development teams.
The key facts for a successful service catalog are the following.
Flexibility
Every company is different and language is fluid, even when it comes to describing the metadata of a service. That’s why development teams might not always use the same terms to describe the same attributes.
A good service catalog lets you define your own taxonomy code and make adjustments if needed.
Portability
A service catalog captures all relevant metadata for the service and keeps it in a single location.
However, it’s not that useful if development teams can’t retrieve this information and use it in their own applications. That’s why the catalog needs to have an easy-to-use API that follows common access patterns to ensure full portability.
Accuracy
A library tool is only as useful as the data it contains. This also applies to a service catalog. And if the data is not up-to-date or correct, it can cause more harm than the actual absence of data.
To keep all data as accurate as possible, a service catalog should have transparent and easy updating processes.
Intelligence
The service catalog is more than just a static, searchable library. It should provide a clear map of the IT infrastructure including the communication streams between all services.
This helps developers get an insight view and covers potential blind spots while increasing their incident response-ability.



/EN/Tools/EA-Maturity-Thumbnail.png?width=260&height=171&name=EA-Maturity-Thumbnail.png)