
In this fourth and final instalment, we leave you with the top machine learning lessons learned from a growing SaaS company, and actionable tips to prepare your company for machine learning techniques.
In part 1 of this series, we defined machine learning and made the connection to enterprise architecture. In part 2, we covered the three types of machine learning algorithms. In our third instalment, explained how to make machine learning algorithms in six steps.
Lessons learned from LeanIX on machine learning
The following are the key lessons which we have learned from our experience with employing machine learning techniques:
If using many services, especially microservices, begin by choosing a unique identifier that serves across all attributing platforms
Having one strong identifier to be used across different platforms will save your team from dealing with inconsistent and inaccessible data sources. LeanIX uses many different services in our daily business activities. If a strong identifier such as a unique customer ID is not designated, it is easy to lose track of customers across different services.
For example - If customer John Doe is identified as #23482558 in Zendesk, JDoe in Salesforce, and jonathanreginald@gmail.com in your email marketing software, his data will be lost, inaccessible, or too inconsistent to reference during machine learning tasks. Even worse: you will be required to spend a lot of time and resources cross-referencing and making your data consistent.
Have a sharp focus on data quality
Data quality refers to the condition of a set of values of qualitative or quantitative variables. Data is considered “high quality” if it fits for its intended use in operations, decision making, and planning.
The International Organization for Standardization (ISO) sets the global standard for Data Quality and Enterprise Master Data. When setting up your database for machine learning projects, you should consider the 15 characteristics defined in the ISO 25012 requirements (see figure 1).
Questions to ask while setting up your machine learning software:
- Is the data accessible?
- Understandable?
- Complete?
It is not necessary to achieve all 15 characteristics, but it is imperative to think about the quality of data while setting up your machine learning database. As an indirect result, your IT landscape will benefit from the improved standards of data quality as well.
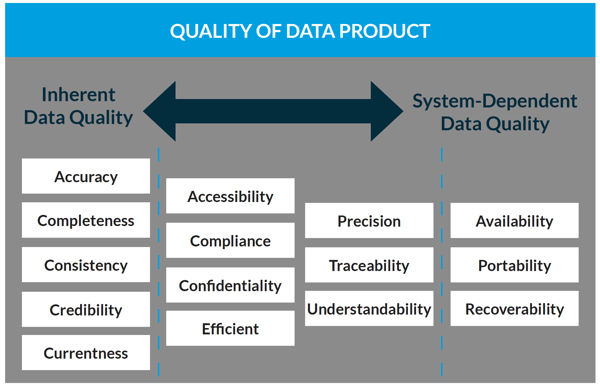
Figure 1: ISO25012 defines a general data quality model.
Figure 1 displays the ISO global standard for data quality. Inherent data quality refers to the degree to which quality characteristics of data have the inherent potential to satisfy stated and implied needs when data is used under specified conditions.
System dependent data quality refers to the degree to which data quality is reached and preserved within a computer system when data is used under specified conditions.
You can control the quality of your system dependent characteristics and you might require some changes in the paradigms of your company in order to have an impact on the data inherent quality characteristics.
Bias in, bias out
To avoid self-fulfilling prophecies in machine learning, be aware of your biases when inputting the data and selecting variables. It is possible to input biased data without realizing it. Techniques for weighting existing data to compensate for unknown bias are randomization, bootstrap sampling, and including more data to the model. Keep in mind that some predictions may be wrong and in turn detrimental to your bottom line. Losing just 5% of your customer base due to systematic errors in your model can be costly.
Correlation does not infer causation
Finding correlation between data samples does not necessarily infer dependency or causation. Two variables that do not correlate prove that there is no significant relationship data, but the converse is not necessarily true. Correlation is generally a measure of the strength of the relationship between two variables but does not directly infer causation.
In the next part of the series, we will cover the 6 steps to making a machine learning algorithm.
A strong correlation between two data samples could mean four things:
- A is caused by B.
- B is caused by A.
- A and B have a common cause.
- The correlation is mere coincidence (if you believe this is the case, then getting more data will resolve your problem and the correlation should disappear. If it doesn’t, then you should analyze critically).
Tip: It is important to think deeper when stumbling upon correlated data.
If you find correlations as a result of your analysis think of what that could mean in terms of your company’s business and analyze accordingly.
Big data analytics require a lot of processing power
Big data is comparable to a voluminous, fast-moving and complex waterfall, and requires a specified supporting system. For some projects, you will have scripts that run for hours or days. To prepare for the exponential velocity of data, it is essential to separate your productive systems from your machine learning querying systems.
Tip: Refrain from using your productive systems to carry out any machine learning queries. Establish a separate cloud-based database for your data science and machine learning tasks, so that the queries and calculations do not impact the product or service that you provide to your customers.
For instance, LeanIX has a business intelligence (BI) and artificial intelligence (AI) server in the cloud which is dedicated to machine learning tasks. There our data scientists and analysts can do their work without affecting our SaaS solution.
Manage expectations of machine learning and artificial intelligence
Popular culture and increasing hype leads us to believe exaggerated ideas about the potential of artificial intelligence and machine learning. The first referenced AI-based topic is usually the heavily hyped self-driving car popularized by Google’s parent company, Alphabet. Although this car is a visionary attribute to the capacity of artificial intelligence, your firm most likely will not be using artificial intelligence in the same ways.
Trained machines perform a very specialized task and carry out that particular task well while failing to perform any other task at all. We are a long way from the same AI driving a car, playing chess, supporting an enterprise’s customer support and analyzing your customer data.
Make sure your managers are aware of the limitations and have reasonable expectations of machine learning and artificial intelligence. Expert systems can be programmed to be ‘better than humans’ for very specialized tasks (e.g. deep learning), but business and enterprise stakeholders should not view machine learning technologies as a magical solution for every minute decision. Don’t be the person/EA that promises a solution the machine cannot possibly keep.
When choosing an algorithm: start simple
For most projects, a simple linear regression or classification will suffice. Avoid starting with complex algorithms like k-nearest neighbors with dynamic time warping on a custom feature space with a custom metric. The sheer technical sophistication of the method will blind you from the true nature of your data. Start with a simple algorithm and gradually progress to more complex algorithms. Strive for a robust and consistent solution. A few things are more frustrating than having a model that predicts very differently on slightly changed input data.
How to prepare your company for machine learning
The line from machine learning to beneficial Enterprise Architects practices can be blurry. Our goal at LeanIX is to use current cutting-edge technologies to make Enterprise Architects’ daily tasks easier.
Tech-savvy Enterprise Architects of tomorrow see the value in staying abreast of all of the current trends, and at the moment, machine learning, artificial intelligence, and deep learning are hot topics. Having the basic knowledge of the possibilities of machine learning allows you to set the framework to benefit from the innovative technique.
Forrester predicts that corporate investment in artificial intelligence will triple in 2017, becoming a $100 billion market by 2025. Preparing for machine learning requires foresight, clear business goals, retraining or hiring of new team members, and having a clear view of your IT landscape.
- First, decide how you want to use machine learning technologies: to automate decision processes, predict user behavior, strengthen customer interactions, improve marketing, define the price of a product in a fluctuating market, approve or deny credit applications, or detect customers with a high risk for churn etc.
- Later, assess the skill set and framework of your company and prepare it for AI. Corporations wishing to spearhead machine learning should place a sharp emphasis on math, statistics, and science. Consider hiring a data scientist - better yet a team of data scientists. They get better when challenging each other.
- Your programmers may be comfortable with other programming languages, but R and Python are the most used language for machine learning. R is the most popular platform for applied machine learning and Python is a general language with a high complexity-performance trade off and has a full suite of tools for productionizing machine learning.
- Lastly, create an AI strategy based on the needs of your enterprise. You may be required to change some paradigms in order to align your company with the benefits and risks of artificial intelligence.
Summary
During this period of rapid digital transformation, companies that do not innovate tend to lose their market share to eager start-ups entering the market. Merrill Lynch predicts that the global market for artificial intelligence and robotics will be just under $153 billion by 2020, and some industries will experience up to a 30% productivity increase through the use of those technologies alone. As machine learning algorithms mimic biological processes and continuously adapt to improve themselves over time, they provide accurate and effective data to increase productivity at your firm.
Machine learning algorithms are a strong tool that may offer Enterprise Architects an abundance of opportunities to continually improve and strengthen business strategies




